Quando se há a necessidade de otimizar uma aplicação, um dos primeiros pontos pensados é o banco de dados. Otimizar o acesso aos dados pode envolver diversos aspectos, entre os mais comuns: a maneira como a aplicação os acessa (bibliotecas, frameworks, …), caching e estrutura (indexação, normalização, criação de views, …). No cenário atual do mercado Java, as aplicações tendem a utilizar a especificação JPA combinada com algum framework que a implementa (como o Hibernate) para “conversar” com o banco. Isso ocorre devido a uma série de benefícios que ela oferece ao desenvolvedor. Entretanto, é normal na área de desenvolvimento o profissional aprender o básico de uma ferramenta e seguir com seu trabalho diário, sem se inteirar sobre os demais recursos que a mesma oferece ou mesmo melhores práticas de utilização. O foco deste artigo é demonstrar ao desenvolvedor dois recursos oferecidos pela versão corrente da JPA que podem auxiliar no processo de otimização voltado para obtenção de dados: carregamento sob demanda e a recuperação somente do necessário.
Cenário-Exemplo
Imagine uma aplicação para gerenciar um estacionamento. Nela existe uma tela básica onde o usuário consegue visualizar todas as vagas (locadas ou não), demonstrada no mockup abaixo:
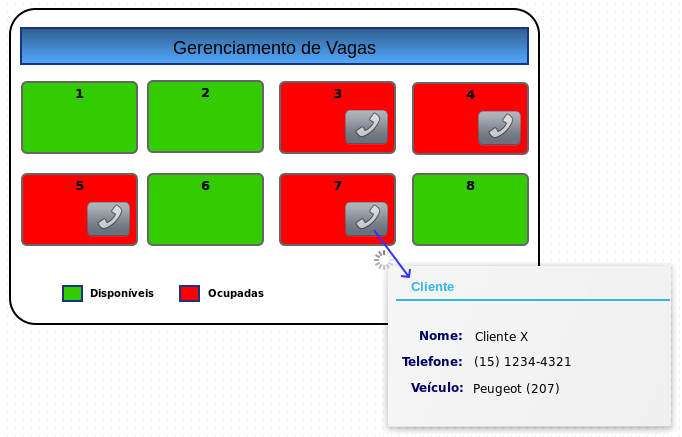
Um dos requisitos dessa tela seria a exibição dos dados do cliente, cujo o veículo se encontra na vaga locada, de uma maneira fácil e rápida. Essa funcionalidade foi implementada como um simples botão. Quando o usuário clica nesse botão, uma chamada assíncrona solicita esses dados e os exibe dentro de uma “janela”. Abaixo está o modelo de dados (entidades) associado a essa funcionalidade:
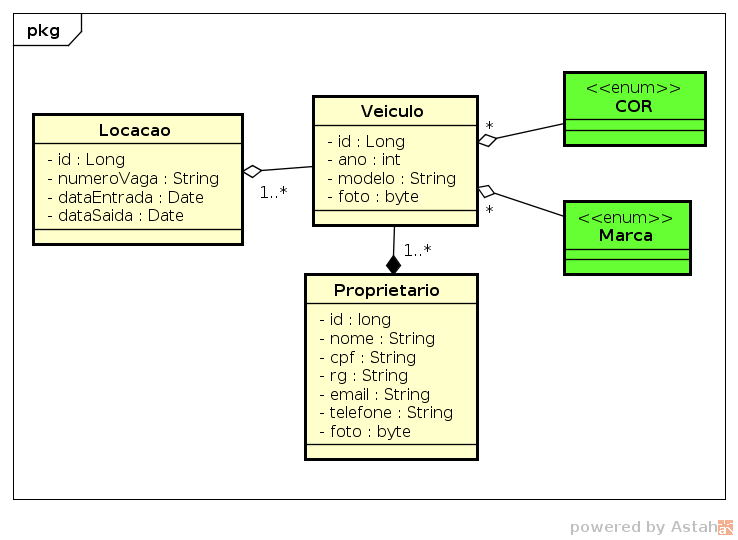
Código Java
O seguinte código Java foi utilizado para implementar o diagrama mostrado anteriormente:

Implementações Possíveis
Essa funcionalidade poderia ter sido implementada de “N” maneiras, porém ficaremos com duas comuns. Na primeira, o programador poderia ter utilizado pré-processadores de view (templates, JSF, JSTL, …), com o código acessando a entidade raiz:
[markdown]
“`
Nome: ${locacao.veiculo.proprietario.nome}
Telefone: ${locacao.veiculo.proprietario.telefone}
Veículo: ${locacao.veiculo.marca} ( ${locacao.veiculo.modelo} )
“`
[/markdown]
Na segunda, existiria um Controlador (padrão MVC) que devolveria somente os dados necessários. Ele retornaria um objeto que seria serializado como JSON por um outro framework (Spring, Struts, …). Posteriormente, esse JSON seria entregue ao código cliente, como no exemplo abaixo:
[markdown]
“`java
public class Controlador {
@PersistenceContext
private EntityManager entityManager;
public ClienteDTO recuperarDadosCliente(Long idLocacao){
Locacao locacao = this.entityManager.find(Locacao.class, idLocacao);
Veiculo veiculo = locacao.getVeiculo();
Proprietario proprietario = veiculo.getProprietario();
ClienteDTO dto = new ClienteDTO();
dto.setMarca(veiculo.getMarca());
dto.setModelo(veiculo.getModelo());
dto.setNome(proprietario.getNome());
dto.setTelefone(proprietario.getTelefone());
return dto;
}
}
“`
[/markdown]
[markdown]
“`java
public class ClienteDTO implements Serializable {
/** */
private static final long serialVersionUID = -6146646091482256095L;
private String nome;
private String telefone;
private Marca marca;
private String modelo;
public ClienteDTO() { }
public ClienteDTO(String nome, String telefone, Marca marca, String modelo) {
this.nome = nome;
this.telefone = telefone;
this.marca = marca;
this.modelo = modelo;
}
// getters e setters omitidos
“`
[/markdown]
Ambas as soluções demonstradas poderiam deixar a aplicação lenta devido ao volume de I/O desnecessário. Isso é causado pela necessidade do JPA ter de carregar todas essas entidades para que a aplicação extraia somente 4 dados (nome, telefone, marca e modelo).
Carregamento sobe Demanda
a) Lazy
Pode ser observado no código das entidades que os relacionamentso para muitos (@OneToMany) estão configurados no modo LAZY (preguiçoso). Essa configuração já é um recurso voltado para a otimização provido pela JPA, tornando o carregamento desses campos sobe demanda. Isso significa que, somente quando o código cliente for acessar o atributo pela primeira vez (através de um “getter”, por exemplo), a JPA interceptará essa chamada para recuperar o seu valor.
Imagine que uma entidade Veiculo fosse recuperada pelo seu “id” utilizando o EntityManager. A JPA teria que carregar somente os campos da mesma não marcados como LAZY. Os marcados, só seriam carregados quando o código cliente chamasse o getter correspondente (getLocacoes(), por exemplo). Esse recurso se mostra interessante, pois imagine que um Veiculo esteja associado a 50 instâncias de Locacao. Toda vez que ele fosse recuperado, a JPA teria que carregar todas essas instância de Locacao ao mesmo tempo. A taxa de I/O poderia aumentar exponencialmente se muitos usuários estivessem recuperando instâncias de Veiculo com essas características.
Por padrão, nos relacionamentos anotados com @OneToMany a recuperação é LAZY (fetch=FetchType.LAZY). Enquanto nos @ManyToOne é EAGER (ansioso), que funciona justamente da forma oposta (carregamento imediato).
b) Basic
Apesar das entidades modeladas terem seus relacionamentos @OneToMany carregados sobe demanda, elas continuam sendo “pesadas”. Principalmente, devido ao atributo “foto” (comum em Veiculo e Proprietario) que é um binário longo. Para resolver esse tipo de problema, a JPA fornece a anotação @Basic. Essa anotação informa como será feita a recuperação de um atributo comum (String, Long, Integer, byte[], …) do banco de dados. Os valores possíveis são os mesmos explicados anteriormente: LAZY ou EAGER (padrão). O atributo “foto” (e talvez outros campos) poderia ter sido configurado como LAZY, para que menos dados fossem carregados nessas entidades:
[markdown]
“`
@Basic(fetch=FetchType.LAZY)
@Lob
private byte[] foto;
“`
[/markdown]
Os recursos explicados anteriormente são importantes e devem ser considerados pelo desenvolvedor. Porém, não seria interessante ter entidades configuradas com todos os seus atributos LAZY. Pois assim, cada vez que um atributo não carregado fosse acessado, a JPA teria de fazer uma consulta dinâmica para obtê-lo. Esse tipo de abordagem poderia sobrecarregar o SGBD. Uma boa solução seria deixar atributos comumente acessados em diversas parte do código configurados como EAGER, e os demais como LAZY. Isso já auxiliaria no processo de otimização, diminuindo o I/O e o tráfego de dados entre a aplicação e o banco.
Recuperando somente o necessário
A JPA fornece um outro recurso para aqueles que não desejam utilizar carregamento sobe demanda. Ela permite a definição de queries (JPQL) que devolvam objetos mais simples (contendo somente os dados que você precisa). Para esse recurso ser utilizado, primeiramente deve-se criar uma classe com os atributos que você utilizará. Essa classe deve ter um construtor contendo cada um dos atributos declarados. Posteriormente, basta se escrever a querie com a palavra chave NEW em conjunto com o construtor qualificado da classe (pacote.classe()) e os dados necessários. Abaixo, o código modificado da classe Controlador utilizando esse recurso:
[markdown]
“`java
public class Controlador {
@PersistenceContext
private EntityManager entityManager;
public ClienteDTO recuperarDadosCliente(Long idLocacao) {
String queryString = “SELECT NEW pacote.ClienteDTO(p.nome, p.telefone, v.marca, v.modelo) ”
+ “FROM Locacao l JOIN l.veiculo v JOIN v.proprietario p WHERE l.id = ?1”;
Query query = this.entityManager.createQuery(queryString);
query.setParameter(1, idLocacao);
return (ClienteDTO)query.getSingleResult();
}
}
“`
[/markdown]
Algumas vantagens dessa abordagem em relação ao carregamento sobe demanda:
- Em aplicações grandes, trocar as configurações das entidades pode signficar quebrar diversas funcionalidades já implementadas (inclusive testes unitários). Como essa abordagem não modifica nenhuma entidade, isso não ocorreria.
- Não há o carregamento de dados desnecessários, consequentemente dimunindo o I/O e o tráfego de dados entre a aplicação e o banco ainda mais.
Conclusão
Otimizar aplicações não é uma tarefa simples e demanda uma boa análise por partes dos desenvolvedores. A JPA é uma especificação robusta na comunidade Java que fornece recursos poderosos para auxiliar nesse processo. Este artigo demonstrou alguns deles. Com essas alternativas em mãos, desenvolvedores podem diminuir consideravelmente o I/O e o tráfego de dados nas aplicações nas quais trabalham.


